在當(dāng)今數(shù)字化與智能化深度融合的時(shí)代,無(wú)論是支撐社會(huì)運(yùn)轉(zhuǎn)的電力配網(wǎng)系統(tǒng),還是承載信息流動(dòng)的網(wǎng)絡(luò)通訊系統(tǒng),其工程的可靠性與效率都至關(guān)重要。實(shí)現(xiàn)這一目標(biāo)的核心路徑在于推行“精細(xì)化設(shè)計(jì)”與“標(biāo)準(zhǔn)化施工”。本文將分別探討配網(wǎng)工程與網(wǎng)絡(luò)通訊工程在這兩方面的關(guān)鍵工藝標(biāo)準(zhǔn)。
一、 配網(wǎng)工程的精細(xì)化設(shè)計(jì)與施工工藝標(biāo)準(zhǔn)
配網(wǎng)工程是電力系統(tǒng)面向用戶(hù)的“最后一公里”,其質(zhì)量直接關(guān)系到供電可靠性、安全性和經(jīng)濟(jì)性。
1. 精細(xì)化設(shè)計(jì)標(biāo)準(zhǔn):
數(shù)據(jù)驅(qū)動(dòng)與精準(zhǔn)建模: 充分利用GIS(地理信息系統(tǒng))、BIM(建筑信息模型)技術(shù),整合地形地貌、既有管線(xiàn)、用戶(hù)負(fù)荷等多元數(shù)據(jù),構(gòu)建高精度的三維設(shè)計(jì)模型。實(shí)現(xiàn)線(xiàn)路路徑最優(yōu)、設(shè)備選型最適配、廊道規(guī)劃最合理。
標(biāo)準(zhǔn)化設(shè)計(jì)與模塊化應(yīng)用: 推行典型設(shè)計(jì),對(duì)架空線(xiàn)路、電纜線(xiàn)路、環(huán)網(wǎng)柜、配電房等制定統(tǒng)一的設(shè)計(jì)標(biāo)準(zhǔn)圖集。采用模塊化設(shè)計(jì)理念,如預(yù)制裝配式配電房、標(biāo)準(zhǔn)化電纜接頭等,縮短設(shè)計(jì)周期,提升設(shè)計(jì)質(zhì)量與復(fù)用率。
* 智能化與可擴(kuò)展性考量: 設(shè)計(jì)階段即預(yù)留自動(dòng)化終端(DTU/FTU)、智能電表、分布式電源接入點(diǎn)以及通信接口,為配電網(wǎng)自動(dòng)化、智能化升級(jí)奠定基礎(chǔ),確保網(wǎng)絡(luò)具備良好的可擴(kuò)展性。
2. 精細(xì)化施工工藝標(biāo)準(zhǔn):
物料與設(shè)備管理標(biāo)準(zhǔn)化: 建立嚴(yán)格的物料準(zhǔn)入與檢驗(yàn)制度,確保電纜、金具、開(kāi)關(guān)柜等設(shè)備符合技術(shù)規(guī)范。推行二維碼/ RFID標(biāo)識(shí)管理,實(shí)現(xiàn)從出廠(chǎng)到安裝的全流程追溯。
關(guān)鍵工序工藝標(biāo)準(zhǔn)化:
* 電纜敷設(shè): 明確直埋、排管、溝道、隧道等不同敷設(shè)方式下的埋深、間距、彎曲半徑、防水防火封堵等工藝要求。
- 電纜接頭與終端制作: 嚴(yán)格執(zhí)行“清潔、剝切、安裝、密封”的標(biāo)準(zhǔn)化作業(yè)流程,確保界面壓力均勻、絕緣恢復(fù)可靠,這是配網(wǎng)安全運(yùn)行的薄弱環(huán)節(jié)管控重點(diǎn)。
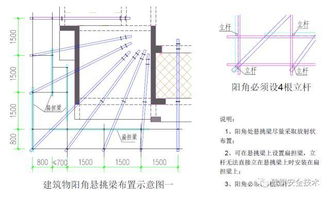
- 桿塔組立與架線(xiàn): 規(guī)范基礎(chǔ)施工、桿塔組裝、導(dǎo)地線(xiàn)展放、緊線(xiàn)與附件的安裝工藝,確保機(jī)械強(qiáng)度和電氣安全距離。
- 現(xiàn)場(chǎng)施工智能化管控: 應(yīng)用移動(dòng)終端進(jìn)行電子化交底、工序報(bào)驗(yàn)和質(zhì)量檢查,實(shí)時(shí)上傳施工影像數(shù)據(jù)。利用無(wú)人機(jī)進(jìn)行線(xiàn)路巡檢和工程進(jìn)度監(jiān)控,提升管理效率和透明度。
- 安全文明施工標(biāo)準(zhǔn)化: 劃定清晰的施工區(qū)域,設(shè)置標(biāo)準(zhǔn)化安全圍擋和警示標(biāo)識(shí)。嚴(yán)格執(zhí)行停電、驗(yàn)電、掛接地線(xiàn)等安全技術(shù)措施,實(shí)現(xiàn)作業(yè)風(fēng)險(xiǎn)的全程可控。
二、 網(wǎng)絡(luò)通訊工程的精細(xì)化設(shè)計(jì)與施工工藝標(biāo)準(zhǔn)
網(wǎng)絡(luò)通訊工程是信息基礎(chǔ)設(shè)施的骨架,其設(shè)計(jì)施工的精細(xì)度直接決定了網(wǎng)絡(luò)的性能、容量和穩(wěn)定性。
1. 精細(xì)化設(shè)計(jì)標(biāo)準(zhǔn):
需求與場(chǎng)景化深度分析: 深入調(diào)研業(yè)務(wù)帶寬、時(shí)延、可靠性、覆蓋范圍、用戶(hù)密度等需求,區(qū)分核心層、匯聚層、接入層進(jìn)行差異化設(shè)計(jì)。針對(duì)數(shù)據(jù)中心、智慧園區(qū)、廣域網(wǎng)等不同場(chǎng)景制定專(zhuān)屬設(shè)計(jì)方案。
網(wǎng)絡(luò)架構(gòu)與路由優(yōu)化設(shè)計(jì): 采用層次化、模塊化的網(wǎng)絡(luò)架構(gòu)(如 Spine-Leaf 架構(gòu)),合理規(guī)劃IP地址、VLAN和路由協(xié)議(如OSPF, BGP),避免環(huán)路,優(yōu)化數(shù)據(jù)流轉(zhuǎn)發(fā)路徑,確保網(wǎng)絡(luò)的彈性和可管理性。
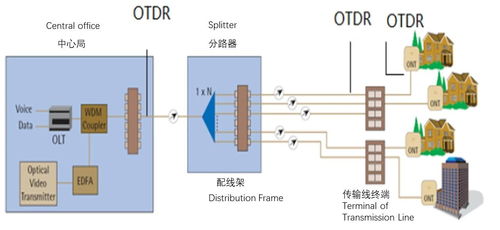
* 物理鏈路與綜合布線(xiàn)系統(tǒng)設(shè)計(jì): 嚴(yán)格依據(jù)國(guó)家標(biāo)準(zhǔn)(如GB 50311)和行業(yè)規(guī)范,設(shè)計(jì)主干與水平子系統(tǒng)。精確計(jì)算光纜/電纜的衰耗、帶寬,選擇合適的光纖類(lèi)型(單模/多模)、線(xiàn)纜類(lèi)別(如Cat6A, Cat7),并詳細(xì)規(guī)劃?rùn)C(jī)柜布局、配線(xiàn)架端口分配及標(biāo)識(shí)系統(tǒng)。
2. 精細(xì)化施工工藝標(biāo)準(zhǔn):
綜合布線(xiàn)施工工藝:
線(xiàn)纜布放: 強(qiáng)電與弱電線(xiàn)纜分離敷設(shè),保持規(guī)范間距。線(xiàn)纜彎曲半徑不得低于標(biāo)準(zhǔn)(如光纜靜態(tài)彎曲半徑≥10倍外徑),綁扎力度適中、整齊。
- 端接工藝: 光纖熔接或機(jī)械接續(xù)需在潔凈環(huán)境中進(jìn)行,熔接后衰耗需嚴(yán)格測(cè)試并記錄。銅纜端接必須按照T568A/B標(biāo)準(zhǔn)線(xiàn)序,使用專(zhuān)業(yè)工具確保接觸可靠。
- 標(biāo)簽與標(biāo)識(shí)系統(tǒng): 全程采用統(tǒng)一的、耐久的標(biāo)簽標(biāo)識(shí),涵蓋線(xiàn)纜兩端、配線(xiàn)架端口、網(wǎng)絡(luò)設(shè)備端口等,實(shí)現(xiàn)“端到端”的清晰可追溯。
- 設(shè)備安裝與配線(xiàn)工藝: 網(wǎng)絡(luò)設(shè)備(交換機(jī)、路由器等)上架安裝應(yīng)牢固、整齊,預(yù)留散熱空間。設(shè)備間跳線(xiàn)應(yīng)長(zhǎng)度適宜、走向清晰,采用理線(xiàn)器規(guī)范整理,避免雜亂。
- 測(cè)試與驗(yàn)收標(biāo)準(zhǔn)化:
- 物理層測(cè)試: 使用FLUKE等專(zhuān)業(yè)儀表對(duì)光纖鏈路進(jìn)行OTDR測(cè)試和雙端衰耗測(cè)試;對(duì)銅纜鏈路進(jìn)行接線(xiàn)圖、長(zhǎng)度、衰減、近端串?dāng)_等性能認(rèn)證測(cè)試。
- 網(wǎng)絡(luò)性能測(cè)試: 完成配置后,需進(jìn)行連通性、帶寬、時(shí)延、丟包率以及網(wǎng)絡(luò)協(xié)議功能的驗(yàn)證測(cè)試。
- 文檔與交付標(biāo)準(zhǔn)化: 施工過(guò)程中同步生成并更新準(zhǔn)確的施工圖紙、測(cè)試報(bào)告、設(shè)備配置文檔和端口對(duì)應(yīng)關(guān)系表,形成完整的竣工資料交付,為后續(xù)運(yùn)維提供精確“地圖”。
###
配網(wǎng)工程與網(wǎng)絡(luò)通訊工程,一“硬”一“軟”,共同構(gòu)成了現(xiàn)代社會(huì)的關(guān)鍵基礎(chǔ)設(shè)施。它們的精細(xì)化設(shè)計(jì)與施工,雖有各自專(zhuān)業(yè)領(lǐng)域的技術(shù)細(xì)節(jié)差異,但核心理念相通:即通過(guò)前期精準(zhǔn)化設(shè)計(jì)規(guī)避潛在問(wèn)題,通過(guò)過(guò)程標(biāo)準(zhǔn)化施工控制質(zhì)量與風(fēng)險(xiǎn),通過(guò)全程數(shù)字化管理提升效率與可追溯性。唯有堅(jiān)持并不斷完善這些工藝標(biāo)準(zhǔn),才能構(gòu)筑起堅(jiān)固、高效、智能的物理能源網(wǎng)與數(shù)字信息網(wǎng),為經(jīng)濟(jì)社會(huì)的高質(zhì)量發(fā)展提供雙重可靠保障。