隨著智能化住宅概念的普及,通信工程已成為現代商品住宅項目中不可或缺的基礎設施建設環節。本文以龍柏二村康健苑商品住宅項目為實例,深入解析其網絡通訊工程從設計到施工全過程的關鍵技術性措施,旨在為同類項目提供實踐參考。
一、 項目背景與設計原則
龍柏二村康健苑項目定位為高品質商品住宅,其通信工程設計需滿足居民當前及未來較長時期內的語音、數據、視頻及智能家居等綜合需求。設計階段遵循了以下核心原則:
- 前瞻性與兼容性:采用光纖到戶(FTTH)為主干,確保千兆乃至未來萬兆接入能力;同時兼顧現有銅纜資源與協議,保證技術平滑過渡。
- 可靠性與冗余性:核心網絡設備與主干光纜路徑采用冗余設計,關鍵節點設置備份,確保網絡服務高可用性。
- 可管理性與安全性:設計集中的網絡管理系統,實現設備監控、故障定位;通過物理與邏輯隔離(如劃分VLAN)保障不同業務與用戶的數據安全。
- 隱蔽性與美觀性:管線設計預先與建筑、裝修方案深度融合,最大限度減少明線敷設,保持室內環境整潔。
二、 關鍵施工技術措施
在施工階段,技術措施的精準落實是保障設計目標實現的關鍵。
- 綜合布線系統施工:
- 垂直干線子系統:在樓宇弱電井內敷設大對數光纜與電纜,固定牢固,彎曲半徑符合規范,并做好清晰、永久的標識。
- 水平配線子系統:采用預埋PVC或金屬管槽方式,從樓層配線間延伸至各戶內信息面板。施工中嚴格管控管線間距,避免與強電線路干擾。
- 工作區子系統:信息插座(如雙口86面板)安裝位置結合家具布局設計,高度統一,端接工藝符合TIA/EIA-568標準。
- 光纜接續與測試:
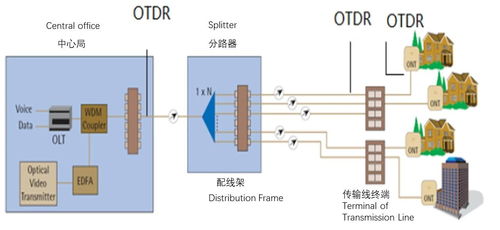
- 采用熔接方式連接光纖,接續點在光纜交接箱內得到妥善保護和固定。
- 使用光時域反射儀(OTDR)和光功率計對每一條光鏈路進行嚴格測試,確保損耗值優于設計指標(如全程損耗≤0.3dB)。
- 設備安裝與調試:
- 機房及樓層配線間的機柜、光配線架、網絡交換機等設備安裝穩固,接地良好,散熱空間充足。
- 進行系統化調試:包括交換機VLAN劃分、路由配置、DHCP服務設置、以及網絡性能(吞吐量、時延)測試,確保端到端連通性與服務質量。
- 防雷接地與防護:
- 所有室外引入線纜加裝信號浪涌保護器(SPD)。
- 建立獨立的弱電系統接地體,接地電阻≤1Ω,并與建筑防雷接地有效等電位連接,保障設備與人身安全。
三、 項目管理與質量控制
本項目的順利實施得益于嚴謹的施工管理:
- 圖紙會審與技術交底:施工前組織各方深入理解設計意圖,明確技術難點與質量標準。
- 材料設備檢驗:所有線纜、接插件、設備進場前進行型號、規格、性能的核查與測試。
- 過程巡檢與隱蔽工程驗收:對管線敷設、接續等關鍵隱蔽工序進行旁站與隨工驗收,留存影像資料。
- 竣工文檔與培訓:編制詳細的竣工圖紙、測試報告和設備配置文檔,并向物業管理部門提供系統操作與維護培訓。
四、 與啟示
龍柏二村康健苑項目的通信工程建設表明,成功的住宅網絡通訊工程依賴于設計與施工的緊密銜接。以用戶需求為導向的先進性設計,配合標準化、精細化、規范化的施工技術措施,是實現網絡系統高性能、高可靠、易維護的根本保障。該項目所積累的經驗,特別是在光纖網絡部署、綜合布線工藝及系統集成測試方面的實踐,為未來智慧社區的通信基礎設施建設提供了有價值的范本。